Active Analytics Platform
Combine a GPU database. real-time location visualization and the power of AI
AI/ML을 위한 Active 분석 워크벤치
- 데이터 수집, 모델 트레이닝/테스팅/배포, 모니터링 및 감사를 단일환경에서 제공합니다.
- 데이터 수집, 모델 트레이닝/테스팅 및 추론을 위한 쿠버네티스 환경을 자동을 구성해줍니다.
지리공간 분석 & Visual 랜더링
- 대규모 위치데이터를 가공/변경 없이 실시간 분석 및 처리가 가능합니다.
- GPU를 통한 빠른 렌더링 기술로 1초 이내에 수 백억건의 데이터 시각화가 가능합니다.
능동적 고급분석
- 메모리 내에서 GPU를 활용한 스트리밍, Historical의 정형/반정형/비정형 데이터를 실시간 수집, 처리 및 분석을 동시에 할 수 있습니다.
- 실시간 다차원 분석 제공 (Aggregation, Sorting, Group by, Filtering 고성능 처리)
Full Text Search 엔진
- 자연어 처리(NLP) 기반 Full Text Search 엔진을 통한 분석 어플리케이션
기술 향상 및 챗봇 등과 같은 인터렉티브 인지 시스템 적용 가능
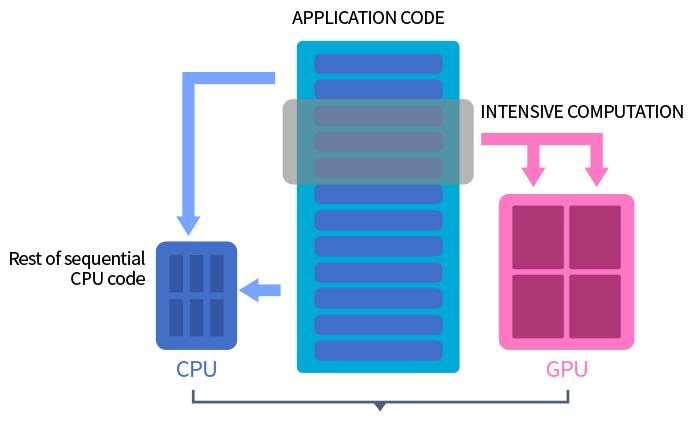
GPU의 가속화된 기술
NVIDIA CUDA API를 활용한 GPU기반 가속화 처리는 대규모 데이터 셋을 병렬 처리하여 CPU로 인해 제한되었던 처리, 분석, 시각화 성능을 극대화합니다.
- Serial Processing을 하는 CPU의 한계를 수 천 코어 GPU 병렬처리를 통해 분석과 시각화 성능을 극대화 하였습니다.
- 초당 수 백만건의 데이터 수집(노드 당 300 TPS 이상)과 동시에 실시간 처리 및 시각화를 수행합니다.
- 모든 범용 표준 서버(on-premiss, 클라우드 등) 지원을 통한 시스템 통합 및 확장이 가능합니다.
GPU의 수 천개의 코어를 통한 MPP 구조의 가속화 분석을 극대화합니다.
최상의 성능을 위해 워크로드에 맞게 CPU, GPU, Memory, DISK 리소스를 적절하게 활용
Job Handling 메커니즘
- INSERT Job: Memory + Disk
- DELETE Job: Memory + Disk
- 단건 UPDATE JOB: Memory + DISK
- SELECT JOB
CPU
- Key index lookup Operation
- Primary-Key Operation
- Primary-Foreign Key Operation
- Column Index 기반 Lookup Operation
- Array Operation
- Between Operation
- Predicate-Join Operation
- Equal-Join Operation
- 기타
- GPU + CPU Job : GIS 및 AI / ML Operation
- GPU Job : GIS Image Rendering
- Lookup() 및 Range 연산에 대해 빠른 쿼리 성능 제공
위치 기반 분석
위치기반 지형분석 엔진은 대규모 데이터의 실시간 위치정보를 분석, 처리, 시각화 합니다. 또한, ESRI, Google, Bing, Mapbox 등의 3rd 파티 맵으로 확장이 가능한 API를 제공하고, 원천 지형기반 형식을 활용하여 수십억 건의 데이터에 대해 실시간 표현이 가능합니다.
- GIS 분석 엔진
- 대량 데이터 위치기반 분석을 위한 API 제공
- 지형데이터 기준의 Query, Filter, Join 등의 연산을 GPU 기반으로 실시간 처리
- 지형공간 이벤트 트리거
- 시각화 및 확장성
- OGC WMS(Web Map Service) Layers
- 3rd Party integration (via API & UDF)
- GPU 기반 동적 데이터 렌더링 기술로 초당 수백억의 데이터 처리 및 시각화
- 모든 지형공간 데이터 형식 지원
- Points, Lines, Polygons, Tracks, Labels 등
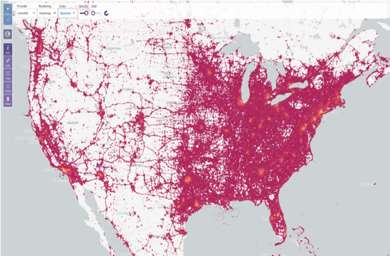
40억건 이상의 트위터 데이터를 별도 처리없이 실시간으로 지도에 표현 가능 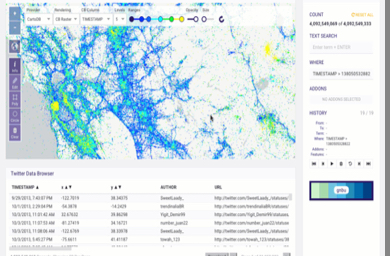
다양한 지형기반 함수를 사용하여 실시간으로 특정 지역에 대한 분석 및 시각화 처리
Visual Discovery & Insight
자체 내장된 시각화 도구(Reveal) 뿐만 아니라, 다양한 BI 도구(Tableau, Caravel, Kibana 등) 연동을 위한 웹기반 시각화 프레임워크를 제공합니다.
또한, 이미 구축된 기업 및 기관의 BI 어플리케이션에도 쉽게 접목할 수 있는 다양한 API 지원을 보장합니다.

- 다양한 접속 언어 지원
- SQL (AMSI 92, 98)
- REST API
- Java, Python, JavaScript, NodeJS, C++ 등
- 다양한 Connector 지원
- kafka, NiFi, ODBC/JDBC, Spark, Storm
- FME(Feature Manipulation Engine)
- Native GIS & IP address object 지원
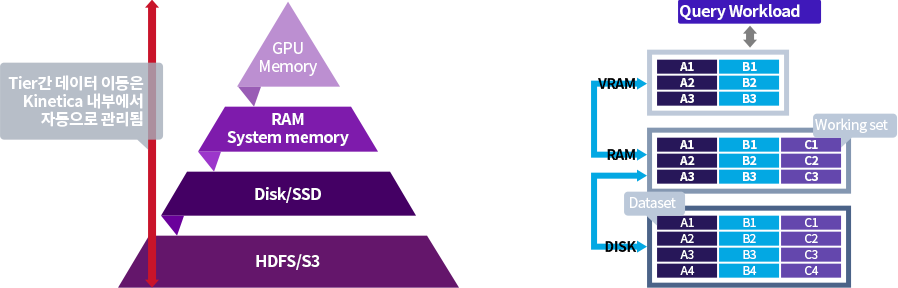
계층화된 저장소(Tiered Storage)
데이터 특성을 고려한 저장공간 관리로 메모리 가용성 극대화
- 데이터 특성에 따라 사용빈도 또는 특정 주기의 데이터만 메모리에 저장 관리
- 글로벌, 테이블, 컬럼 단위 계층 전략 구성 가능
- 테이블 파티션 구조를 설정하여 데이터 로딩 속도 향상(Chunk Skipping) 및 메모리 상주 기간 설정 가능
- 사용자 그룹에 따른 메모리 사용 범위를 제어하여 안정적인 운영 가능(특정 사용자로 인한 부하 방지)
- 디스크캐시, COLD 영역 설정을 통해 처리속도 보장 및 하드웨어 ROI 개선
- 활용도가 빈번한 디스크 캐시 영역만 SSD로 구성하고 나머지 공간은 SATA 방식 디스크 설계
- COLD(HDFS, S3, 로컬마운트)를 통한 저비용으로 데이터 연속성 확보
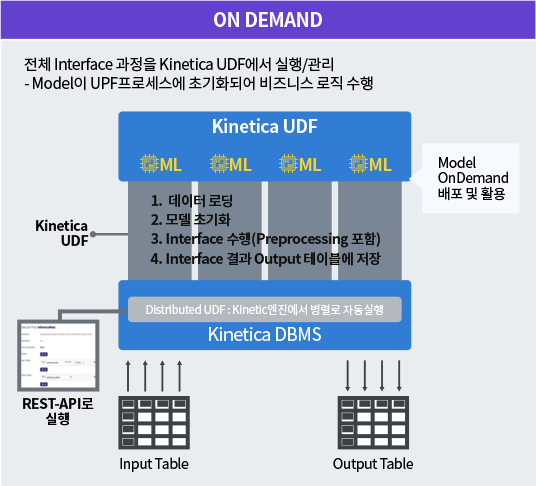
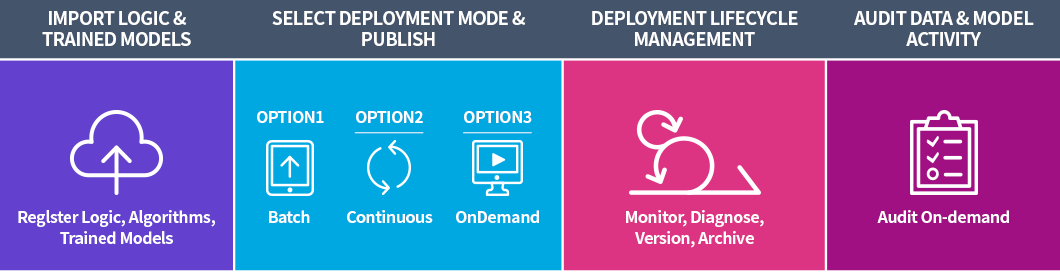
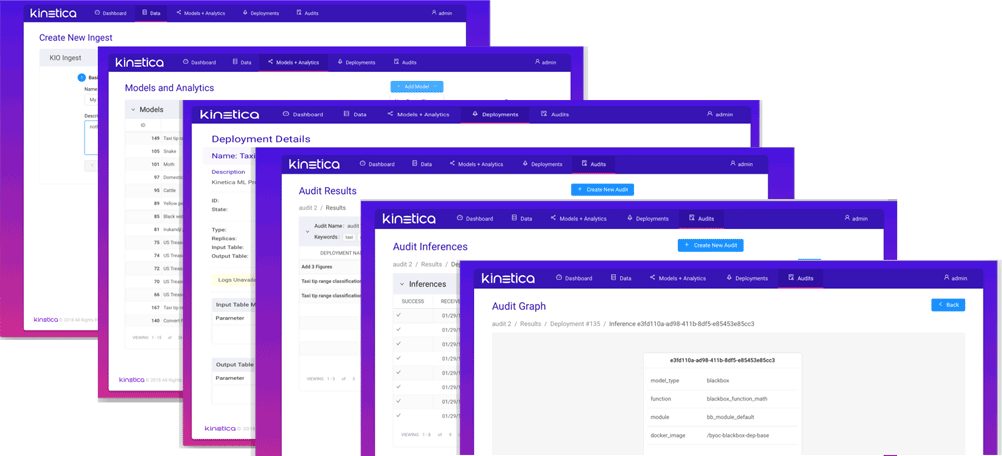
AI/ML을 위한 Active 분석 워크벤치
데이터 수집, 모델 트레이닝/배포, 모니터링 및 감사를 단일 환경에서 제공
- 데이터 수집(Ingest)
- Streaming(Kafka), Batch(Kinetica, Postgres, S3) 방식 지원
- 모델 (Model / Analytic)
- TensorFlow(Built-in Template 모델), Black Box(사용자 작성 모델)
- Tensorflow, PyTorch, BIDMach 등 다양한 Library 지원
- 배포(Deployment)
- On Demand, Continuous, Batch 방식 배포
- 감사(Audit)
- 모델 트레이닝, 테스팅 과 추론 정상 여부 확인
- 키워드, 날짜 범위 기준으로 생성되고 입력 파라미터, 프로세스 상태 등을 통해 추론 필터링하여 감사
- 설정 정보, Featureset, Dataset 과 추론 결과 DB 저장 => 데이터 과학자 협업, 메타 데이터 및 의존성 추적 관리 등 용이
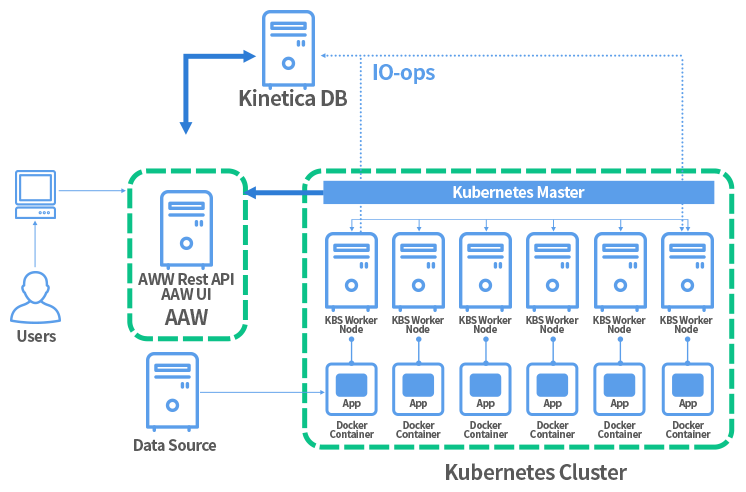
AI/ML을 위한 Active 분석 워크벤치(계속)
데이터 수집, 모델 트레이닝/테스팅 및 추론을 위한 쿠버네티스(K8s) 환경 자동 구성
- Enterprise 급 인프라 환경 및 기능 제공(K8s)
- Automatic binpacking: 조건과 제약사항에 고려하여 컨테이너 자동 배치
- Self-healing: 반응이 없는 컨테이너 등을 재시작
- Batch execution: 배치를 실패한 컨테이너 교체
- Load balancing: IP 주소와 DNS을 이용해 로드밸런싱
- Resource Management : 효율적인 자원 할당 및 사용률 추적 기능 등
AI/ML을 위한 Active 분석 워크벤치(계속)
데이터 수집, 모델 트레이닝/테스팅 및 추론, 모든 과정의 운영 및 관리를 위한 Dashboard 환경 제공
AI/ML을 위한 개발 환경 연계
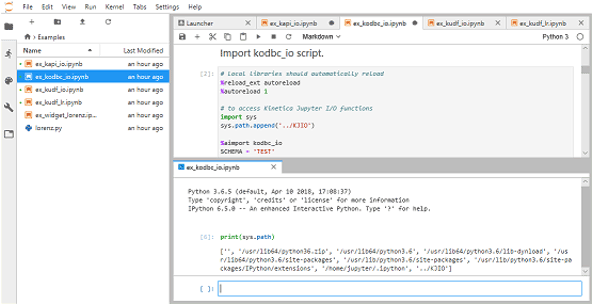
모델 개발을 위한 JupyterLab Tutorial 제공
- JupyterLab Tutorial
- 구성 요소 통합을 위한 Docker 이미지 제공을 통해 프로세스 간소화
( JupyterLab, Kinetica 6.2, CentOS 7, Python 3.6 )
ODBC 또는 원시 API를 사용하는 Kinetica와의 상호 작용
Kinetica UDF 생성 및 실행
ML 모델 실행 (예 : Pandas, PyTorch, TensorFlow) - 모든 Intel 기반 컴퓨터 환경에서 실행 가능
- 구성 요소 통합을 위한 Docker 이미지 제공을 통해 프로세스 간소화
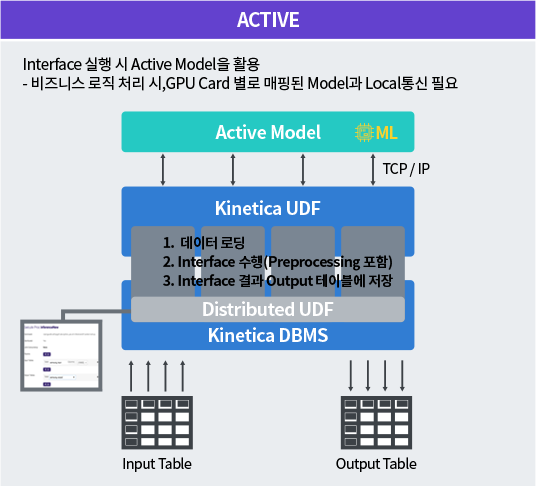
AI/ML을 위한 Active 분석 워크벤치
기 생성된 모델의 Inference 성능을 향상시키기 위해 키네티카 설정 만으로 병렬처리 극대화 가능